

Opinions expressed in this article are solely my own and do not express the views or opinions of my employer.
The challenge(s)
So, you decided to run your containerised applications on Kubernetes, because everyone seems to be doing it these days. Day 0 looks fantastic. You deploy, scale, and observe. Then Day 1 and Day 2 arrive. Day 3 is around the corner. You suddenly notice that Kubernetes is a microcosmos. You are challenged to make decisions. How many clusters should I create? Which tenancy model should I use? How should I encrypt service-to-service communication?
STAY TUNED
Learn more about DevOpsCon
Decision #1, multi-tenancy
Security should always be job-0, if you do not have a secure system, you might not have a system.
Whether you are a Software-as-a-Service (SaaS) provider or simply looking to host multiple in-house tenants, i.e., multiple developer teams in a single cluster, you will have to make a multi-tenancy decision. There’s a great deal of difference in how you should approach multi-tenancy given the use cases.
No matter how you look at it, Kubernetes (to date) was designed as a single-tenant orchestrator from the ground up. The temptation to ‘enforce’ a multi-tenant setup using (for example) namespace isolation is considered a logical separation which is far from a secure approach.
Let’s look at the following diagram to understand the challenge.
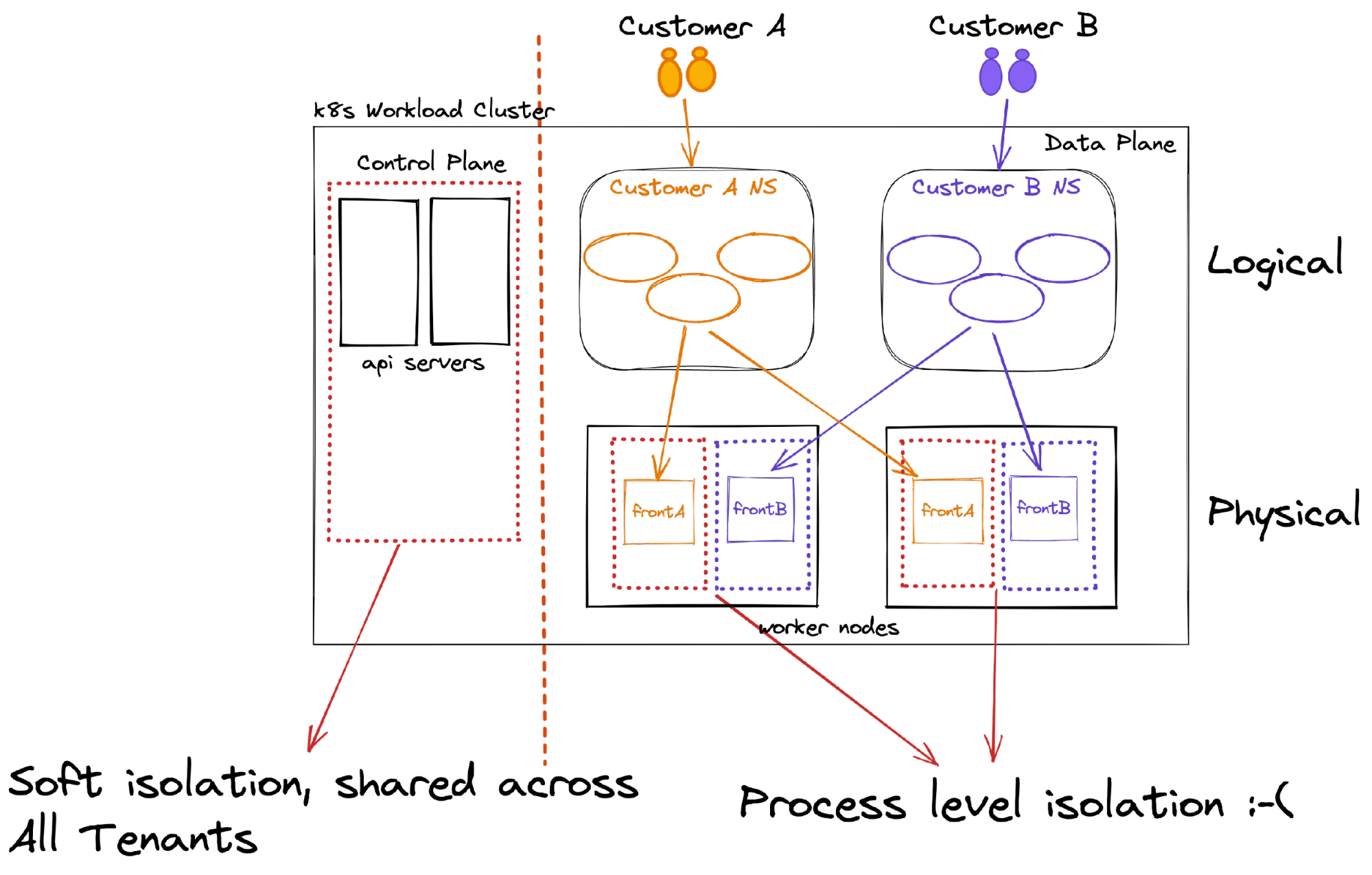
The control plane
The k8s control plane is a cluster-wide shared entity; you enforce access to the API and its objects by enforcing RBAC permissions, but that’s (almost) all you got, my friend. In addition, RBAC controls are far from easy to write and audit, increasing the likelihood of the operator making mistakes.
You may ask yourself what’s the ‘big deal,’ however, imagine the scenario where a developer needs to write an app that needs to enumerate the k8s API, and unintentionally, the app has a k8s identity which allows it to list all the k8s namespaces. This means that you just potentially exposed the entire set of customer names that runs on your cluster.
Another example could be a simple exposed app configuration which allows the tenant to enrich log entries with k8s constructs(pod) fields. This has the potential to saturate the k8s API, rendering it inoperable. While capabilities such as API Priority and Fairness can help in mitigation (enabled by default), it is still considered runtime preventative protection rather than strong isolation.
The data plane
Containers provide process-level isolation running on the same host, sharing the same single kernel, that’s all. So, with only k8s namespace isolation, tenants will share the same compute environments pretty much as running multiple processes on the same virtual machine (well, almost). When extending the k8s namespace isolation with tenant affinity, resulting (tenant=namespace=dedicate compute), your tenants still share the same networking space.
Kubernetes offers a flat networking model (out of the box); a pod can communicate with any pod/node regardless of its data-plane location. Very often, network policies are used to limit this access to specific approved flows, i.e., all pods in namespace-a can access all pods in namespace-b but not namespace-c. This practice is still considered a soft-isolation tenancy as the tenants will share the same networking namespace. However, it will mitigate the noisy neighbor effect as tenants are collocated (affinity) onto specific dedicated compute resources.
So how do we make a decision? There seem to be so many vectors to consider. The answer, like anything in architecture, stems from business requirements, risk analysis, constraints, and the extraction of tools and technologies which will mitigate gaps.
In the next section, we start by first defining tenant profiles and then showcase a few tenancy use cases and their corresponding patterns.

Trusted/untrusted tenant/code
It is crucial to first determine whether your tenants can be trusted or if their corresponding applications run untrusted code.
A trusted tenant could be applications, services, and developers aligned to a certain division, i.e., a developer from team prod-a. This tenant is part of the organization’s security policy. It is up to the organization’s leadership to decide what and who is considered a trusted tenant (it even might be developers, contractors, or partners). It is up to the cluster operators to translate the trusted entities into the corresponding operational tenancy model, reflecting the threats and risks to the organization’s leadership.
An untrusted tenant normally refers to entities which reside outside the organization’s boundaries, hindering the ability of the organization to enforce its security policy. In large multi-hierarchy organizations, it is not unlikely to declare certain departments as untrusted tenants. Services and developers running untrusted code (see untrusted code explained in the next section) are to be considered untrusted tenants.
Untrusted code means that your code (or code you did not write/audit) may include low-level OS system calls or require escalated privileges which in the event of a container escape may lead to catastrophic consequences that could result in other tenants’ breaches. If your applications must provide your tenants the possibility to run untrusted code (especially if they are considered untrusted tenants), I would recommend isolating this workload into a dedicated cluster/boundary. This pattern is often referred to as untrusted/hard isolation.
Use cases for the untrusted/hard isolation pattern range from k8s as Platform-as-a-Service (PaaS), apps which mandate privilege access (host level), apps which can execute arbitrary code in a container, to apps with unfettered access to the k8s API.
The following HLD depicts the untrusted/hard isolation pattern.

Trusted/soft isolation, on the other hand, builds on the Kubernetes namespace concept. It isolates tenants logically within a logical boundary called a namespace. The operator can define per-namespace resource quotas to enforce a fair share of resources within a namespace. As well as set Limit Ranges on the pod level.
Logical isolation means that multiple tenants’ pods will share the same compute nodes and cluster-wide resources. Due to those reasons, this soft isolation pattern use cases fit trusted tenants. Use cases can range from developer teams sharing the same cluster to very mature SaaS applications which achieve strong tenant isolation on the application level.
The following HLD depicts the trusted/soft isolation pattern.

I am also able to spot trends which extend the trusted/soft isolation pattern, adding tenant affinity to dedicated nodes.
The following HLD depicts the trusted/soft isolation/affinity pattern.
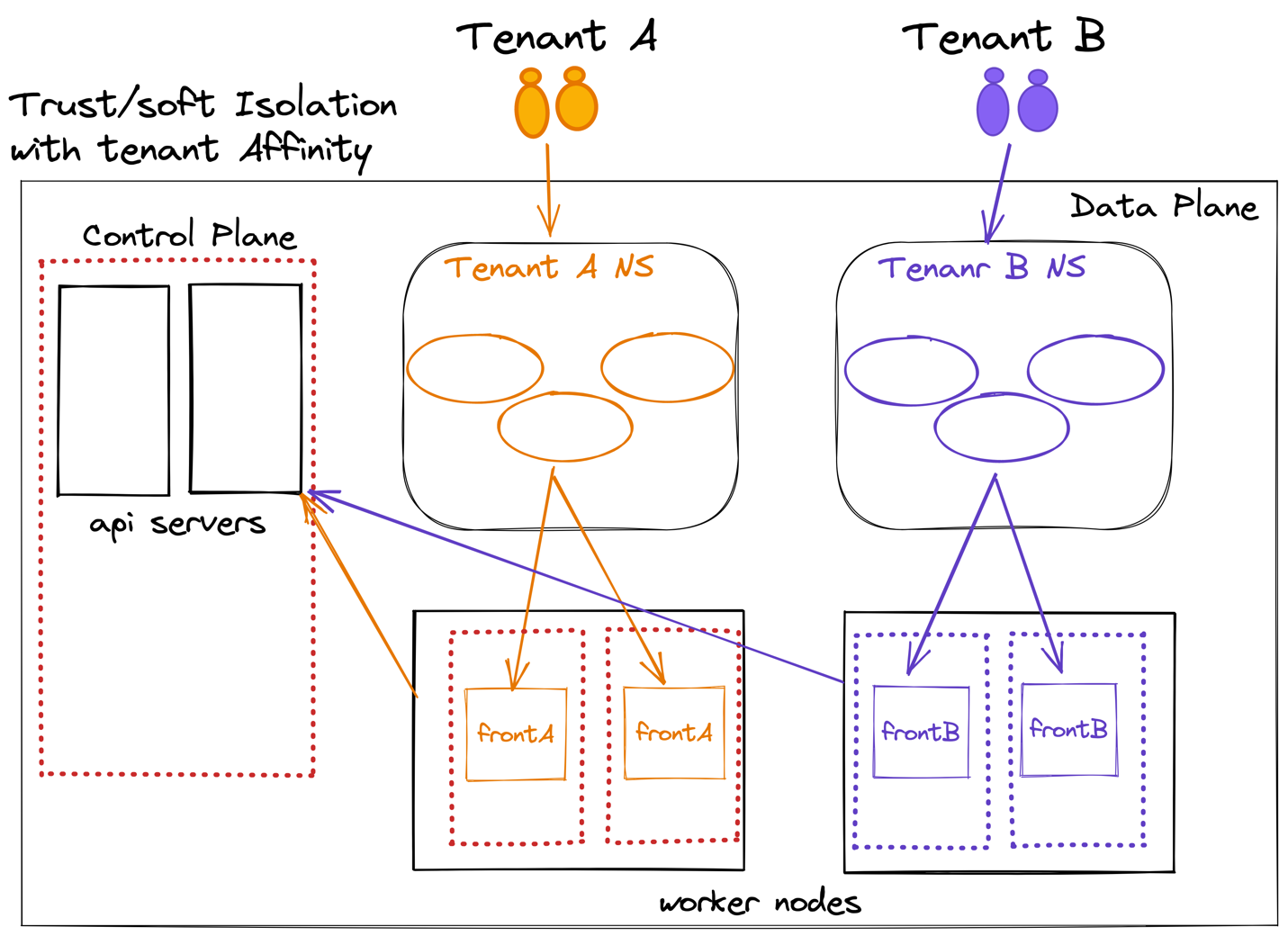
This pattern will solve the noisy neighbor effect and will provide a better day-2 tenant upgrade/update experience (tenants=NodeGroup). On the other hand, the k8s flat networking model still means soft isolation.
STAY TUNED
Learn more about DevOpsCon
Is it a zero-one endgame?
So now that we have those three patterns, what happens when we are in the process of SaaSifying our applications/services? Should we wait until we finish the process? How should we tackle ‘old’ application(s), and un-secure design patterns?
An example based on previous experience included a CMS system hosting a particular microservice which allowed users to execute untrusted code. The architect team ended up building a software-based scenario engine that the customer would use to upload the code, controls, and scenario. In return, the platform team would spin up a (short-lived) dedicated k8s cluster which executed the scenario and using the async bus, reported the result to the main application APIs (hosted on a multi-tenant cluster).
You get the idea: isolate any apps or services that don’t meet the multi-tenant paradigm and collaborate with the software architect teams to find modern solutions. Do not compromise on Job-0 (security).
Regardless of the pattern(s) you choose, you are encouraged to implement common defense-in-depth techniques, so let’s explore those.
The common: defense-in-depth across all tenancy patterns
The following diagram depicts the controls that (at min) should be implemented.

It is beyond this blog to dive into the controls mentioned above. They are to be implemented across all patterns. The objective is to mitigate the vertical attack vector (i.e., Pod to host), and horizontal attack vector (i.e., Pod to cluster data plane nodes).
Conclusions
- Multi-tenancy is everyone’s responsibility. It’s the organization’s leadership which defines the business profiles (eventually translated into tenants). The CTO is in charge of ensuring that the developer teams write multi-tenant-aware applications. It is up to the platform teams to convert the business profile into a secure architecture. The CISO is the one who shapes and approves the tenant threat model.
- Do not bring the ‘old’ into the new, modernize and SaaSify your application while carefully considering the tenancy patterns. An old pattern could be an untrusted tenant which uses VPN to connect to designated pods (running privileged VPN server containers) in order to execute code or send data.
- Mixing multiple tenancy patterns can and should be used to bridge the gap for a true application-level multi-tenancy. At the same time, do not obsess about true application-level multi-tenancy. It often takes years to get there, especially if the application(s) is not modern. It’s perfectly OK to use multiple tenancy patterns to bridge this gap.
- My advice is not to fall into deterministic definitions; trusted and untrusted are used to bridge the gaps between the organizational leadership and the operational teams. I have seen internal developers which were declared untrusted tenants due to permission to run untrusted code inside pods, posing cluster-wide risks.
Where to go from here?
You get the idea; there is no “Enable multi-tenant cluster mode” tick box which will split the cluster into VM-level isolated spaces. It is your responsibility to work backwards from the business requirements, choose the proper pattern, and enforce controls to implement.
New technologies are emerging, providing VM-level-like workload isolation for containers. To learn more on those check Firecracker, Kata Containers, and gVisor.
Decision #2, purpose-built container operating system?
Most of the containers (to date) are still hosted on virtual machines installed with mainstream Linux operating systems: Debian-based; Vendor-based Linux OS. So, you may ask yourself: And? Is that a problem? Well, it’s not a ‘problem’ in terms of functionality per se. Traditional operating systems were not designed to be “Just enough OS to run containers.”
Challenges observed:

- Security – Installing and updating extra packages simply to satisfy dependencies can increase the attack surface, and most of the time those packages are not needed.
- Updates – Traditional package-based update systems and mechanisms are complex and error-prone and can have issues with dependencies, leaving a fleet of virtual machines in an inconsistent state, increasing the attack surface and vulnerability.
- Overhead – Extra, unnecessary packages consume disk space and compute cycles and also increase startup time.
- Drift – Inconsistent packages and configurations can damage the integrity of a cluster over time.
Most cloud providers will use those traditional OS as a starting point to vent their own version of a container-optimized OS. At the core, those include kubelet (the k8s agent), container runtime (i.e., containerd), Network CNI plug-in, and bootstrap scripts, allowing the nodes to successfully register and connect to the k8s API servers. However, those are still based on fully blown Linux OS distros, containing package managers, and a large number of installed packages which are simply not relevant for running container workloads.
Purpose-built operating systems are a paradigm shift in the operating system domain. They are built from the ground up for one sole purpose: Running container workloads. Hence, they will be fast, secure (limited attack vectors), and adhere to the defense-in-depth principle. At the core, they will still provide kubelet, container runtime, Network CNI plug-in, and bootstrap scripts, often modified to meet the secure surface.
I am a big fan of container purpose-built OS; CoreOS spearheaded this effort releasing what is known as CoreOS Container Linux. This led to multiple vendor innovations on that namespace: CoS(GCP), Bottlerocket(AWS), and FlatCar(Azure).
So why should you consider a purpose-built OS? Here’s a list of features that a few of them showcase:
- No package managers
- SELinux/AppArmor (enforced)
- Kernel lockdown
- Read-only root filesystem
- API-driven configuration
Some features might be supported/enabled on purpose-built distro-a and not on distro-b.
This is not a curated list of the features/characteristics, but you get the idea, it could fit very well into your defense-in-depth security paradigm. See this diagram that depicts it:

STAY TUNED
Learn more about DevOpsCon
In this example, an attacker escapes a container and is able to gain access to the host namespace. The attacker (as root) is trying to load a malicious kernel module. This will fail due to a feature called kernel lockdown (given the feature is available and enabled). Not to get confused, all the runtime controls you know well should be implemented in the first place in order to prevent a container escape.
Considering the above, often your workloads might not meet the purpose-built OS paradigm. Those operating systems very often require that all software, including operational (log agents and runtime protectors), runs as containers and not as binary processes in the OS host namespace. In other cases, actions such as modifying configuration files will fail or will not persist due to the read-only or tmpfs OS immutability principle.
Conclusions
- Purpose-built container OS should be your first choice OS.
- Prefer purpose-built container OS which can be deployed anywhere (cloud, on-premises), the reason being the amount of overhead you might spend on customization.
- OS customization is very limited with purpose-built container OS
- In use cases where your OS customization is wide and deep, purpose-built container OS might mean significant management overhead to a larger attack surface. In those cases, consider not to opt in.
To sum up
In this article, I have highlighted a few choices that enterprises will need to make if they decide to implement a Kubernetes platform. I hope that you find this decision analysis useful. I am curious to know if I was successful in sparking in-depth discussions within/across your teams. So what’s next? Stay tuned for the next part of this article series.
Opinions expressed in this article are solely my own and do not express the views or opinions of my employer.



